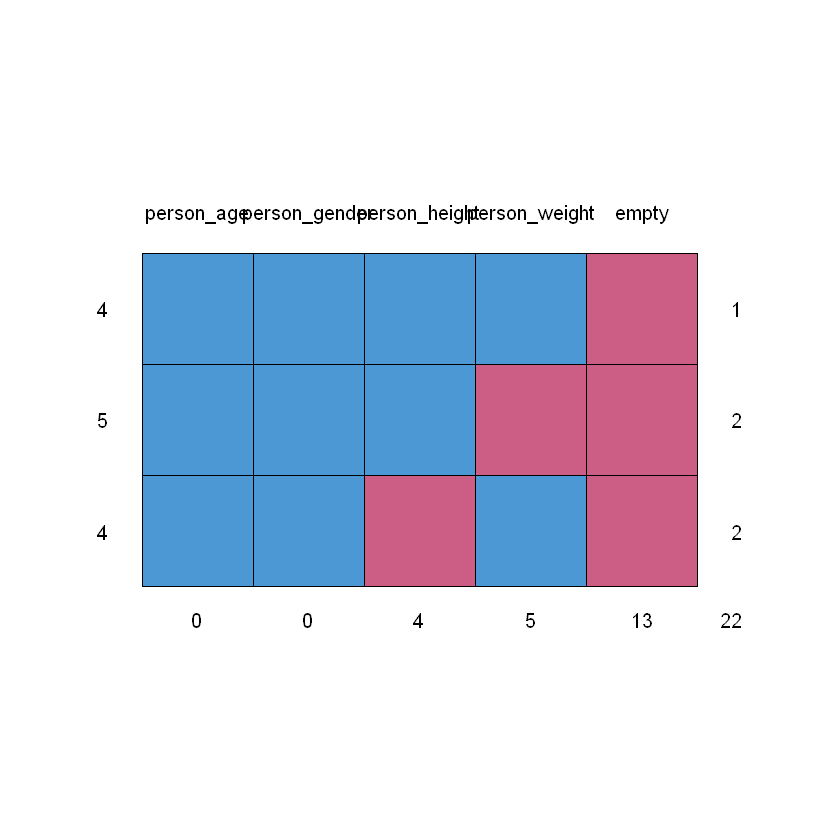23Заміна пропусків у даних (Missing Value Imputation)
author: Юрій Клебан
Дані реального світу часто мають відсутні значення. Дані можуть мати відсутні значення з ряду причин, таких як спостереження, які не були записані, пошкодження даних, неспівставність форматів даних тощо.
Проблема - [x] Обробка відсутніх даних важлива, оскільки багато алгоритмів машинного навчання або програм для візуалізації та аналізу даних не підтримують дані з відсутніми значеннями.
Рішення
Примітка
Некоректна інформація в даних може бути записана різними способами, наприклад у датасеті ці дані можуть бутьу визначені як NA<NA>NULLundefindedUndefined. Перед обробкою таких даних усі невизначені записи варто конвертувати у NA.
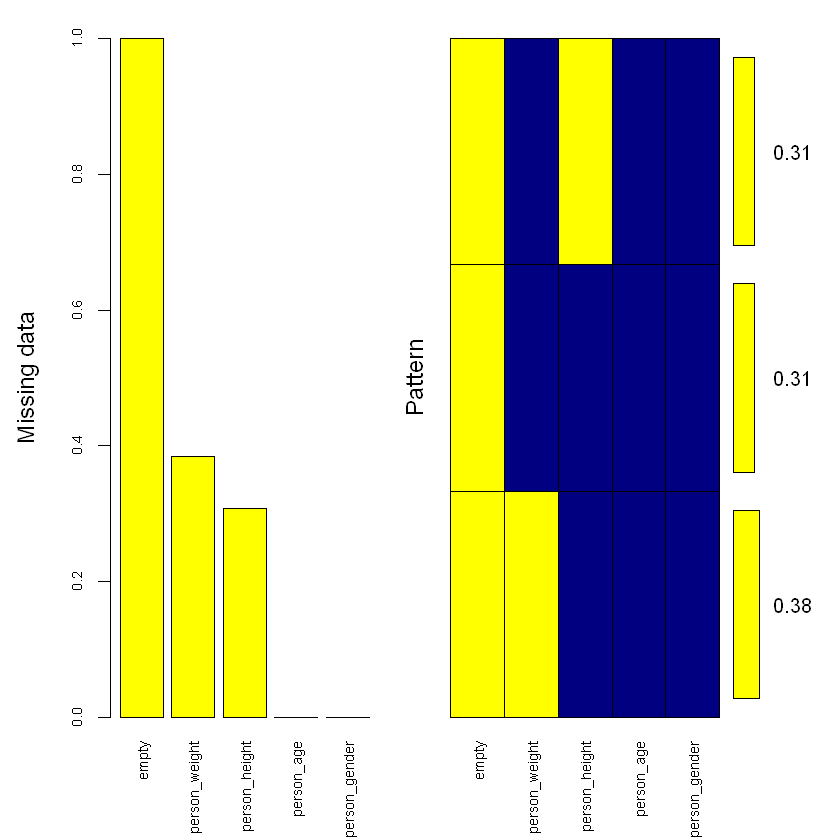
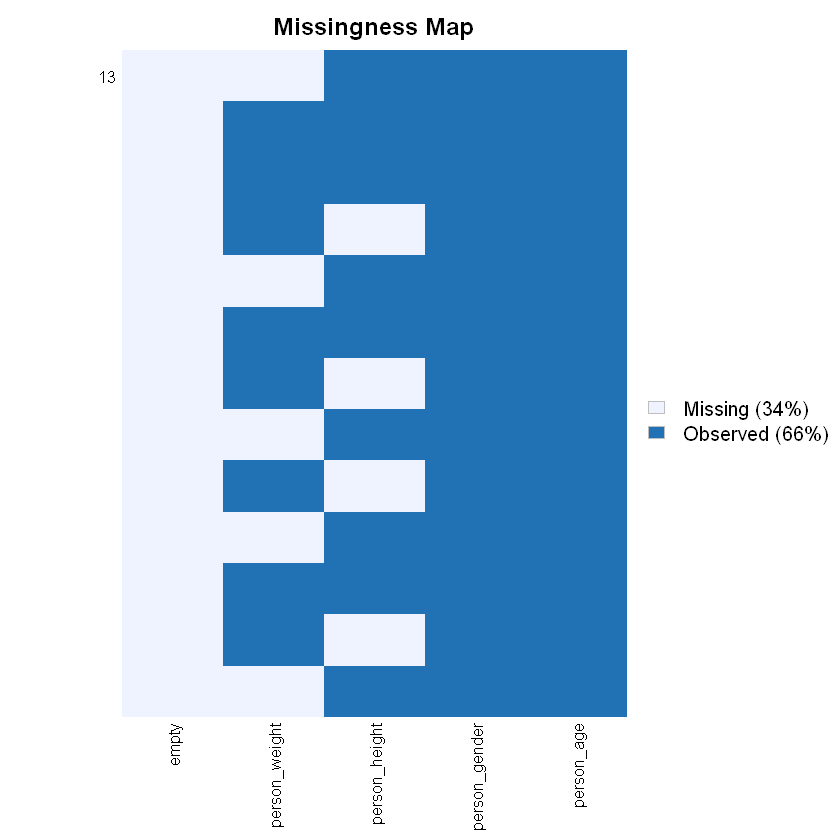
Щоб переглянути список усіх стовпців, що мають пропуски даних можна скористатися наступним кодом:
Також можна скористатися альтернативними макетами: missForest, mi.
23.2 Видалення пустих рядків та сповпців у data.frame
Переглянемо стовпці, що містять пропуски:
# Переглянемо список стовпців з пропускамиcolnames(data)[apply(data, 2, anyNA)]
Your code contains a unicode char which cannot be displayed in your
current locale and R will silently convert it to an escaped form when the
R kernel executes this code. This can lead to subtle errors if you use
such chars to do comparisons. For more information, please see
https://github.com/IRkernel/repr/wiki/Problems-with-unicode-on-windows
'person_height'
'person_weight'
'empty'
Функція complete.cases повертає логічні значення
complete.cases(data) # бо є стовпець Empty
Your code contains a unicode char which cannot be displayed in your
current locale and R will silently convert it to an escaped form when the
R kernel executes this code. This can lead to subtle errors if you use
such chars to do comparisons. For more information, please see
https://github.com/IRkernel/repr/wiki/Problems-with-unicode-on-windows
FALSE
FALSE
FALSE
FALSE
FALSE
FALSE
FALSE
FALSE
FALSE
FALSE
FALSE
FALSE
FALSE
Також видаляти стовпці та рядки з data.frame можна за допомогою пакету janitor.
library(janitor)data_cleaned <-remove_empty(data, which =c("rows","cols"), quiet =FALSE)data_cleaned# Видаляємо повністю пусті
Your code contains a unicode char which cannot be displayed in your
current locale and R will silently convert it to an escaped form when the
R kernel executes this code. This can lead to subtle errors if you use
such chars to do comparisons. For more information, please see
https://github.com/IRkernel/repr/wiki/Problems-with-unicode-on-windowsNo empty rows to remove.
Removing 1 empty columns of 5 columns total (Removed: empty).
Щоб переглянути усі записи, що не мають пропусків скористаємося функцією na.omit():
na.omit(data_cleaned)
A data.frame: 4 × 4
person_age
person_height
person_weight
person_gender
<int>
<int>
<dbl>
<chr>
2
41
175
68.3
male
3
11
142
55.4
female
6
32
168
78.0
female
11
41
20
81.0
female
Таким чином пропущені значення будуть видалені з датасети, якщо інформацію переприсвоїти data <- na.omit(data)
23.3 Заміна пропусків у data.frame
Існує ряд підходів, що використовуються для заміни пропущених значень у датасеті:
Заміна на 0 * Вставте пропущені значення нулем
Заміна на медіану/середнє значення * Для числових змінних - середнє або медіана, мінімум, максимум * Для категоріальних змінних - мода (бувають випадки, коли моду доцільно використовувати і для числових)
Сегментна заміна * Визначення сегментів * Обчислення середнього/медіани/моди для сегментів * Замінити значення по сегментах * Наприклад, ми можемо сказати, що кількість опадів майже не змінюється для міст у певній області України, у такому випадку ми можемо для усіх міст з пропусками записати значення середнє по регіону.
Інтелектуальна заміна (Частковий випадок сегментної заміни) * Заміна значень з використанням методів машинного навчання
23.3.1 Заміна пропусків на нуль (0)
data <-read.csv("data/cleaned_titled2.csv")data
A data.frame: 13 × 4
person_age
person_height
person_weight
person_gender
<int>
<int>
<dbl>
<chr>
23
185
NA
male
41
175
68.3
male
11
142
55.4
female
12
NA
48.2
male
54
191
NA
female
32
168
78.0
female
22
NA
54.0
male
21
165
NA
male
14
NA
90.2
male
51
250
NA
female
41
20
81.0
female
66
NA
59.0
male
71
171
NA
male
Замінимо інформацію про вагу з пропусками на 0:
data_w0 <- data |>mutate(person_weight =ifelse(is.na(person_weight), 0, person_weight))data_w0
A data.frame: 13 × 4
person_age
person_height
person_weight
person_gender
<int>
<int>
<dbl>
<chr>
23
185
0.0
male
41
175
68.3
male
11
142
55.4
female
12
NA
48.2
male
54
191
0.0
female
32
168
78.0
female
22
NA
54.0
male
21
165
0.0
male
14
NA
90.2
male
51
250
0.0
female
41
20
81.0
female
66
NA
59.0
male
71
171
0.0
male
# Без dplyrdata_w0 <- datadata_w0[is.na(data_w0$person_weight), "person_weight"] <-0data_w0
Your code contains a unicode char which cannot be displayed in your
current locale and R will silently convert it to an escaped form when the
R kernel executes this code. This can lead to subtle errors if you use
such chars to do comparisons. For more information, please see
https://github.com/IRkernel/repr/wiki/Problems-with-unicode-on-windows
A data.frame: 13 × 4
person_age
person_height
person_weight
person_gender
<int>
<int>
<dbl>
<chr>
23
185
0.0
male
41
175
68.3
male
11
142
55.4
female
12
NA
48.2
male
54
191
0.0
female
32
168
78.0
female
22
NA
54.0
male
21
165
0.0
male
14
NA
90.2
male
51
250
0.0
female
41
20
81.0
female
66
NA
59.0
male
71
171
0.0
male
Зробити заміну для усіх числових стовпців:
library(tidyr) # for replace_na()data_all <- data |>mutate_if(is.numeric , replace_na, replace =0)data_all
A data.frame: 13 × 4
person_age
person_height
person_weight
person_gender
<int>
<int>
<dbl>
<chr>
23
185
0.0
male
41
175
68.3
male
11
142
55.4
female
12
0
48.2
male
54
191
0.0
female
32
168
78.0
female
22
0
54.0
male
21
165
0.0
male
14
0
90.2
male
51
250
0.0
female
41
20
81.0
female
66
0
59.0
male
71
171
0.0
male
23.4 Числова заміна пропусків
Заміна на константи або обчислені значення є стандарним підходом. Так, наприклад, заміна певного значення на середнє матиме вигляд:
data_m <- data |>mutate(person_weight =ifelse(is.na(person_weight), mean(data$person_weight, na.rm = T), person_weight))data_m
A data.frame: 13 × 4
person_age
person_height
person_weight
person_gender
<int>
<int>
<dbl>
<chr>
23
185
66.7625
male
41
175
68.3000
male
11
142
55.4000
female
12
NA
48.2000
male
54
191
66.7625
female
32
168
78.0000
female
22
NA
54.0000
male
21
165
66.7625
male
14
NA
90.2000
male
51
250
66.7625
female
41
20
81.0000
female
66
NA
59.0000
male
71
171
66.7625
male
Заміна на min, max, median не відрізняється.
Якщо виникає потреба замінити, наприклад, усі значення на медіану у всіх стовпцях за один прохід можна скористатися функцією mutate_if():
Розглянемо кілька бібліотек для перевірки даних на наявність пропусків…
Ще одним із варіантів заміни значень може бути використання бібліотеки Hmisc:
#install.packages("Hmisc")
library(Hmisc)data_wm <- data |>mutate(person_weight =impute(data$person_weight, fun = mean)) # mean imputation# Аналогічно можна замінити на min,max, median чи інші функціїdata_wm # * Значення із * - замінені
Your code contains a unicode char which cannot be displayed in your
current locale and R will silently convert it to an escaped form when the
R kernel executes this code. This can lead to subtle errors if you use
such chars to do comparisons. For more information, please see
https://github.com/IRkernel/repr/wiki/Problems-with-unicode-on-windows
A data.frame: 13 × 4
person_age
person_height
person_weight
person_gender
<int>
<int>
<impute>
<chr>
23
185
66.7625
male
41
175
68.3000
male
11
142
55.4000
female
12
NA
48.2000
male
54
191
66.7625
female
32
168
78.0000
female
22
NA
54.0000
male
21
165
66.7625
male
14
NA
90.2000
male
51
250
66.7625
female
41
20
81.0000
female
66
NA
59.0000
male
71
171
66.7625
male
23.4.0.1 Hot deck imputation (як перекласти???)
Метод Hot deck imputation передбачає, що пропущені значення обчислюються шляхом копіювання значень із подібних записів у тому ж наборі даних.
Основне питання при Hot deck imputation полягає в тому, як вибрати значення заміни. Одним із поширених підходів є випадковий відбір:
# set.seed(1)data_hot <- data |>mutate(person_weight =impute(data$person_weight, "random")) data_hot
A data.frame: 13 × 4
person_age
person_height
person_weight
person_gender
<int>
<int>
<impute>
<chr>
23
185
59.0
male
41
175
68.3
male
11
142
55.4
female
12
NA
48.2
male
54
191
55.4
female
32
168
78.0
female
22
NA
54.0
male
21
165
54.0
male
14
NA
90.2
male
51
250
90.2
female
41
20
81.0
female
66
NA
59.0
male
71
171
54.0
male
Вихідне значення залежить від значення seed.
23.5 Сегментна заміна пропусків
Заміна по сегментах часто дозволяє будувати точніші математичні моделі, адже групові середні краще описують явища і процеси, ніж загальні для всієї вибірки.
Знайдемо середні значення ваги за статтю та використаємо ці значення для заміни пропусків у даних.
data_sgm <- data |>group_by(person_gender) |>mutate(person_weight =replace_na(person_weight, mean(person_weight, na.rm =TRUE)))data_sgm
A grouped_df: 13 × 4
person_age
person_height
person_weight
person_gender
<int>
<int>
<dbl>
<chr>
23
185
63.94000
male
41
175
68.30000
male
11
142
55.40000
female
12
NA
48.20000
male
54
191
71.46667
female
32
168
78.00000
female
22
NA
54.00000
male
21
165
63.94000
male
14
NA
90.20000
male
51
250
71.46667
female
41
20
81.00000
female
66
NA
59.00000
male
71
171
63.94000
male
Також можна здійснити заміну значень по усіх стовпцях датасету за один раз. Проте не варто такий підхід використовувати постійно, а враховувати бізнес-логіку процесів, що вивчаються.
data_sgm2 <- data %>%group_by(person_gender) %>%mutate(across(everything(), ~replace_na(.x, min(.x, na.rm =TRUE))) )data_sgm2
A grouped_df: 13 × 4
person_age
person_height
person_weight
person_gender
<int>
<int>
<dbl>
<chr>
23
185
48.2
male
41
175
68.3
male
11
142
55.4
female
12
165
48.2
male
54
191
55.4
female
32
168
78.0
female
22
165
54.0
male
21
165
48.2
male
14
165
90.2
male
51
250
55.4
female
41
20
81.0
female
66
165
59.0
male
71
171
48.2
male
Якщо ж є потреба замінювати по окремих стовпцях, то їх можна вказати замість everything(): across(c("person_height", "person_weight"), ~replace_na(.x, min(.x, na.rm = TRUE))).
Іншим варіантом може бути вказання номерів колонок: across(c(1,3), ~replace_na(.x, min(.x, na.rm = TRUE)))
23.6 Інтелектуальні методи заміни
Теоретично інтелектуальні методи заміни пропусків є найкращими, адже враховують математичні залежності у даних.